这次,分享分享正则表达式,真实工作环境中做代码审计,合理的使用正则表达式,可以大幅度的提高工作效率。
背景
现在很多的 Java 项目的鉴权,都是引入鉴权组件,然后以注解的方式去做的。
比如:@JianQuanAPI(name="dashboard", auth=Auth.NONE, cluster="intranet")
那做接口的代码审计时,在保证鉴权组件内逻辑无误的情况下,最需要关心的就是注解的配置与身份信息的提取了。
而我现在想做的,就是从项目的成千上万个接口注解中,提取出“未鉴权”与“低鉴权”的接口,然后进一步审计这些接口是否符合“不需要鉴权”或者“低鉴权”的要求且内部逻辑是否存在其他逻辑类风险。
使用 IDEA 自带的正则匹配搜索,难点就在于,注解中的配置可能会存在顺序不一致、缺省属性等,我需要尽可能的不漏匹配。
分析
目前的鉴权注解(示例数据):@JianQuanAPI,具体在实例中看:
其中包含几个属性,意义分别是:
- name: 接口 url;
- auth: 鉴权类型。 NONE – 不鉴权; WEAK – 弱鉴权; AUTH – 强鉴权;
- cluster: 集群类型。 intrannet – 内网; internet – 互联网
目标:
我需要匹配 name 以 bashboard 开头,且 type 为 NONE 但 cluster 不为 intrannet 的(内网情况下允许不鉴权)
开始行动:
先复习一下正则表达式基础,然后就开始实例尝试一下
代审之正则表达式基础
- 字面字符。
- 元字符:
.(匹配任意单个字符)、*(匹配前一个元素0次或多次)、+(1次或多次)、?(0次或1次) - 字符类:
[abc](匹配 a/b/c 中的任意一个)、[^abc](匹配非 a/b/c 中的任意一个) - 分组:
(...)(用于组合模式或者捕获匹配结果) - 转义:
\(匹配元字符本身) - 空白匹配:
\s(匹配空白字符。空格、制表符、换行符等) - 量词:
{n}(n 次)、{n,}(至少 n 次)、{n,m}(n 到 m 次)
代审之正则表达式进阶
贪婪匹配(默认行为)
量词(包含元字符)会尽可能的匹配多的字符。
比如:
- 正则:
a.*b - 文本:
axbzb - 结果:会匹配
axbzb,而不是axb
非贪婪匹配
在量词后面加 ?,会尽可能的匹配少的字符,也是 ? 本身的意义(0 个或者 1 个满足条件就匹配成功)。
比如:
- 正则:
a.*b - 文本:
axbzb - 结果:会匹配
axb,遇到第一个b就停止匹配
\b单词边界
\b 匹配“单词边界”(单词开始或结束的位置),而不是一个实际字符。
比如:
- 正则:
\bname\b - 文本:
name = ... - 结果: 匹配成功,因为表达式中 name 是一个单词,如果文本是
username = xxx就会匹配失败,因为在这个表达式中username才是一个单词,而name只是部分字母。
\bname\b
\bname
\sname\s三者的区别是什么?
\bname是匹配以name开头的单词,\b是单词边界的意思
\sname\s也是匹配一个name单词,但是同样会匹配上两端空格
\bname\b会匹配所有符合\sname\s的场景,并且不会包含空格,且还会匹配到譬如,、"、_等符号隔开的场景。
断言(零宽预查)
普通正则表达式是从左到右依次匹配的,匹配满足之后就继续向右了。而断言,是“零宽”的,它只检查条件是否满足,而不消耗字符(不移动匹配的位置)。经常用于多条件匹配。共有 4 种(前面 2 种比较常见):
正向先行断言(?=...)
检查当前位置之后是否匹配 pattern,但不消耗字符,如果匹配则继续,否则匹配失败。
比如:
- 正则:
password(?=\d) - 文本:
password123 - 结果:匹配成功。因为这个表达式意义是,匹配
password且仅当其后面紧跟数字(\d)。所以password匹配失败(后面没有数字),passwords匹配失败(后面也没有数字,只有一个字母s),password123匹配成功(后面是数字)
负向先行断言(?!...)
检查当前位置之后是否不匹配 pattern。如果不匹配则继续,否则匹配失败。
比如:
- 正则:
password(?!\d) - 文本:
password123 - 结果:匹配失败。因为这个表达式意义是,匹配
password且仅当其后面不是数字。所以passwords可以匹配成功(后面是字母s),password也可以匹配成功(后面什么都没有),但password1匹配失败(后面是数字)
正向后行断言(**?<=...**)
检查当前位置之前是否匹配 pattern。但是这里:pattern 必须是固定长度写法。
比如:
- 正则:
(?<=pass)word - 文本:
password - 结果: 匹配成功,因为
word前面匹配pass,如果是p@ssword就会匹配失败。
负向后行断言(?<!...)
检查当前位置之前是否不匹配 pattern。
比如:
- 正则:
(?<!wang)xiaoming - 文本:
wangxiaoming、zhangxiaoming - 结果:
wangxiaomign匹配失败、zhangxiaomign匹配成功,如果这是个name列,相当于是匹配所有不姓wang的xiaoming。
实例
我的项目中,鉴权就是使用注解完成的,注解中有很多属性。
public @interface JianQuan {
/**
* 负责人
*/
String author() default "";
/**
* API的名称
*/
String name() default "";
/**
* API的版本
*/
String version() default {};
/**
* 集群(内网时可以不需要鉴权)
*/
Cluster cluster() default Cluster.common;
/**
* 登录和鉴权
*/
Type auth() default Type.NONE;
/**
* API的描述
*/
String desc() default "";现在,我想筛选出:
name属性以bashboard.开头(我今天要审计的功能模块);- 且
auth的值为Auth.NONE(没有配置鉴权,也就是未授权); - 且没有
cluster配置,或者cluster的值不为Cluster.intranet(非内网集群)
的代码行。
非内网集群的未授权接口,大概率会存在未授权访问或者越权漏洞。
如下这是一个示例,我来依照这个示例完善正则表达式,但是要注意,注解内的属性顺序可能不固定。
@JianQuan(name = "bashboard.list", version = "1.0", author = "xxx", desc = "看板列表", auth = Auth.NONE, cluster = Cluster.intranet)
第一步:匹配 @JianQuanAPI(xxx) 注解所在的行
正则表达式:@JianQuanAPI\(.*\)
匹配
@JianQuanAPI注解,内部可以是任意字符
问题:默认是贪婪匹配,如果出现多个 ) ,可能会匹配到最外面一个,不过理论上来说,只要代码是正确的,注解行时不会出现这种情况的,但既然学的是正则,那还是严谨一点
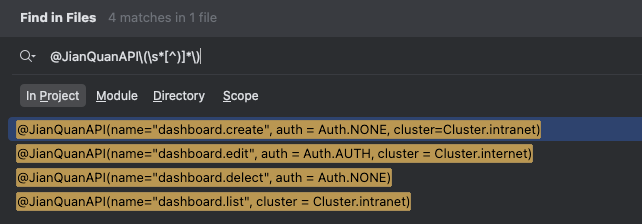
优化:@JianQuanAPI\(\s*[^)]*\)
优化成了
[^)]*, 意为多个不为)的字符。\s*是考虑任意个空位。
第二步:添加属性条件,先加 name
思路:
- 属性顺序不确定,name 可能在 auth 前面,也可能在后面,所以,用正向肯定预查,不依赖顺序。
- \b 来匹配 name 单词
- name 的值包裹在双引号
"内,所以 name 的值要匹配非"(和上面一样,理论上来说正确的代码不会出现这种问题,但学习处于严谨考虑还是加上限制)
正则表达式:@JianQuanAPI\(\s* 这里加入对属性的匹配条件 [^)]*\)
name属性匹配条件:\bname\b\s*=\s*"dashboard[^"]+"
\b来匹配name单词,\s*匹配=两端,允许出现 0 个或者多个空格,[^"]+用来匹配一个或者多个非"的字符
继续优化一下:因为要忽略属性的顺序,也就是说 name 属性前面可能还会有别的属性,所以,name 的匹配条件前面,再加一个 [^)]*? ,意为非贪婪匹配任意不是 ) 的字符,只要能找到 name匹配条件就行。
优化后的 **name** 属性匹配条件:?=[^)]*?\bname\b\s*=\s*"dashboard[^"]+"
接下来,构建预查询语句(?=),然后将 name 属性匹配条件用小括号括起来(组合模式),得到
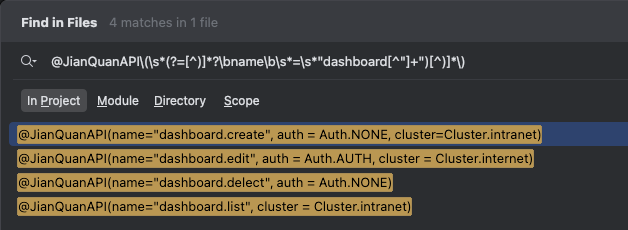
正则表达式:@JianQuanAPI\(\s*(?=[^)]*?\bname\b\s*=\s*"dashboard[^"]+")[^)]*\)
第三步:添加第二个属性条件,auth
和 name 一样
正则表达式结构:@ThorApi\(\s* (?=name条件)(?=auth条件) [^)]\)
auth属性匹配条件:\bauth\b\s*=\s*Auth\.NONE\b
同 name 一样,由于顺序不强制要求,所以前面也允许 [^)]*? 非贪婪匹配,并构建预查询语句
得到正则表达式:
@JianQuanAPI\(\s*(?=[^)]*?\bname\b\s*=\s*"dashboard[^"]+")(?=[^)]*?\bauth\b\s*=\s*Auth\.NONE\b)[^)]*\)
第四步:排除第三个属性条件,cluster
思考:
首先,如果 cluster 不存在,也就是没有这个属性,那应该是要匹配的,所以不需要刻意写这个条件,我们只需要处理「不匹配
cluster = Cluster.intranet」 的场景即可。不匹配,那就是用负向预查询(
?!),而至于规则,与name和auth就类似了,不需要贪婪匹配,使用非贪婪匹配,只要发现cluster = Cluster.intranet,直接就可以停止了
正则表达式结构:@JianQuanAPI\(\s* (?=name条件)(?=auth条件)(?!cluster条件) [^)]\)
cluster 条件:[^)]*?\bcluster\b\s*=\s*Cluster\.intranet\b
基本上同上,唯一不同的是这次构建的是负向预查询 ?!
得到正则表达式:
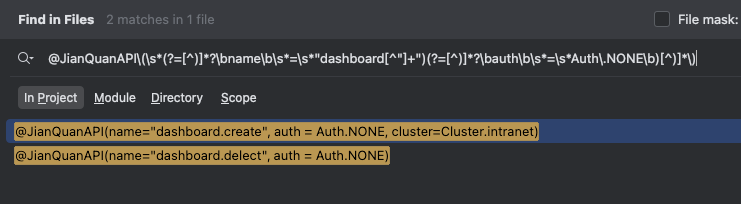
@JianQuanAPI\(\s*(?=[^)]*?\bname\b\s*=\s*"dashboard[^"]+")(?=[^)]*?\bauth\b\s*=\s*Auth\.NONE\b)(?![^)]*?\bcluster\b\s*=\s*Cluster\.intranet\b)[^)]*\)
这样,就得到了完整的正则表达式,测试一下效果
第五步:补充 —— 我遗漏了一个场景
经过实测之后,我发现,我遗漏了一种情况,就是当没有 auth 属性的时候,由于它的默认值就是 Auth.NONE,所以,我还需要捕获这种情况。
这里先补充一个语法:
?:: 非捕获分组。
最开始「基础」中有提到
(xxx)的作用是分组,默认就是捕获分组,用来捕获匹配结果。而?:就是写在分组括号内的最前面,来表示这个分组不需要捕获,就像这样(?:xxx)。
理论上来说,分组捕获还是不捕获,并不会影响正则的匹配结果,它只会影响捕获结果。(就像我们代审时,我只需要匹配出我需要的代码即可,并不需要处理捕获结果)。而捕获,通常是应用在开发语言中的,因为开发语言中会对正则表达式匹配并捕获到的结果做进一步处理。
所以很多开发语言中,也会对正则表达式升级「命名分组」,防止后续对正则表达式进行调整后,所捕获的分组出现乱序。
思路:
- 先把之前的正则表达式拿过来,找到关于 auth 的匹配条件,留出占位符
- 编写关于 auth 的匹配条件
- 匹配
auth = Auth.NONE或者不存在auth属性,也就是说,出现 0 次或者 1 次,但可以不写,我们只需要禁止它以外的出现,剩下的就是它或者不存在的场景;- 不匹配
auth = Auth.NONE以外的任何场景,也就是说,如果出现了auth,且值不为 NONE,就匹配失败- 将其作为分组,填充回原来留的占位符中,得到完整正则表达式
原始正则:
@JianQuanAPI\(\s*(?=[^)]*?\bname\b\s*=\s*"dashboard[^"]+")(?=[^)]*?\bauth\b\s*=\s*Auth\.NONE\b)(?![^)]*?\bcluster\b\s*=\s*Cluster\.intranet\b)[^)]*\)
留出空位:
@JianQuanAPI\(\s*(?=[^)]*?\bname\b\s*=\s*"dashboard[^"]+") auth 相关的规则 (?![^)]*?\bcluster\b\s*=\s*Cluster\.intranet\b)[^)]*\)
auth 相关的规则:
匹配 auth 不存在或者存在但不为 NONE,也就是禁止匹配 auth = Auth.XXX 其中 XXX 不为 NONE 这种场景。
(?![^)]*?\bauth\b\s*=\s*Auth\.(?!NONE\b)\w+\b)
构造完整的正则表达式:
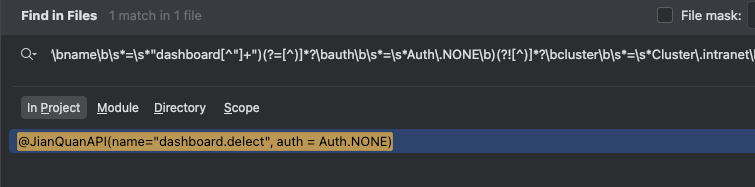
@JianQuanAPI\(\s*(?=[^)]*?\bname\b\s*=\s*"dashboard[^"]+")(?![^)]*?\bauth\b\s*=\s*Auth\.(?!NONE\b)\w+\b)(?![^)]*?\bcluster\b\s*=\s*Cluster\.intranet\b)[^)]*\)
正则表达式这个东西,要精确的话太复杂了,可能还有很多没有考虑到的特殊场景需要优化,但是目前作为人工代码审计来说,可以将大量的几千个接口过滤到符合条件的十来个接口,已经足够了,即使有遗漏的特殊场景,人工也能看出来。
当然如果想作为一个扫描工具使用的话,那这个正则表达式可能还需要多喂一些样本数据来继续优化一下。